- 简介 > InfiniBand是一种开放标准的高带宽,低时延,高可靠的网络互联技术。该技术由IBTA(InfiniBand Trade Alliance)定义推动在超级计算机集群领域广泛应用,同时,随着人工智能的兴起,也是GPU服务器首选的网络互联技术。目前,最新的InfiniBand产品为Mellanox生产的HDR,可以为网络提供端到端高达200Gbps的带宽,为高性能计算,人工智能等领域带来无与伦比的网络体验,最大程度释放集群内计算潜能。 - 为什么我们需要InfiniBand? - 带宽高,400 Gb/s 的超快的速度。下面展示了端口宽度分别为1X、2X、4X和12X。带宽在2018年中期达到600GB/s的数据速率(HDR)和2020年的1.2TB/S数据速率(NDR)。  图1 InfiniBand Roadmap - 低延迟,端到端延迟大概为1µs,因此大大加速了许多数据中心和高性能计算(HPC)应用程序。 -  - 更加高效,支持先进可靠的传输协议,比如RDMA(Remote Direct Memory Access)来提高作业的处理效率。 - InfiniBand和以太网的区别? | | InfiniBand(12x) | 万兆以太网 | | -------- | -------------------- | ------------------------------------ | | 带宽 | 168G,300G... | 10G | | 延迟 | 小于等于1微秒 | 接近10微秒 | | 应用领域 | 超级计算机、企业存储 | 互联网,城域网等 | | 优点 | 低延迟,高带宽 | 应用范围广,已成为普遍认可的标准技术 | | 缺点 | 硬件成本高 | 延迟难以进一步降低 | - 基于IB的应用? - RDMA - MPI - NVLink - UCX ## 他所存在的不足? - 拥塞控制问题 - Background - 采用基于信用的链路层流控 - 基于显式拥塞通告(Explicit Congestion Notification, ECN)的端到端拥塞控制技术。[^[1]]:曹光权,张子文,孙志刚,陈洪义,胥庆杰.基于ibdump的InfiniBand网络拥塞控制观测方法研究[J].计算机科学,2013,40(04):47-50. **拥塞控制原理:** 从宏观角度来看,拥塞控制操作可以分为三步: - 第一步,①当交换机检测到拥塞发生,交换机会将IB数据包的BTH(Base Transport Header)中的FECN(Forward Explicit Congestion Notification)域置为1。 - 第二步,②当数据包到达目标HCA(Host Channel Adapter) ③目标HCA会向源HCA返回带BECN(Backward Explicit Congestion Notification)标识的CNP(Congestion Notification Packet) 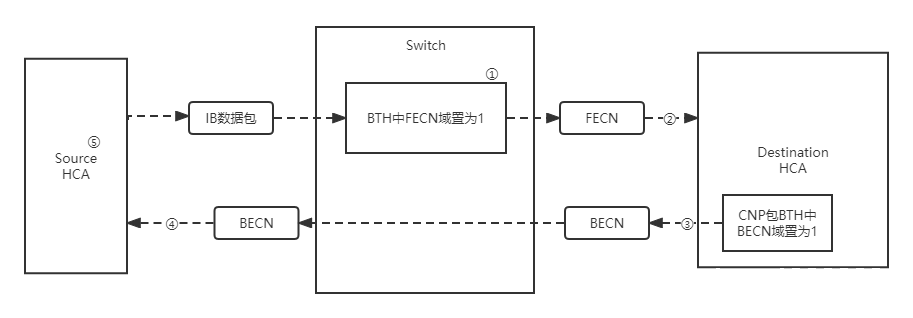 图2 IB网络中的拥塞控制架构 - 第三步,④当源HCA收到CNP, ⑤它会逐渐减少发送速率,从而减少拥塞随着时间的推移,源 HCA会逐渐恢复发送速率。 lB网络的拥塞控制需要IB交换机 HCA都支持才能选择开启,IB交换机和HCA维持着有关拥塞控制的一系列参数,这些参数决定着交换机什么时候检测到拥塞 、以什么样的比率进行FECN标记、HCA降低发送速率的速度和时长, 如果这些参数进行了合理的设置,网络就会很好地解决拥塞问题 ,避免头堵塞 (head-of-lineblocking),从而更充分利用网络资源。 - Question - 定期更新的信用混淆了拥塞控制。 - 端到端IB CC缓慢的调整速率与快速的基于信用的逐跳流量控制不匹配。 - Congestion-unaware rate increase contradicts with rate decrease. ## 可能的解决方案 要做到更好的拥塞控制我认为应该实现以下的目标: - 准确的检测和识别拥塞流。 - 迅速的将拥塞流量降低到适当的速度,而不是逐步降低。 解决方案: 一、接收者驱动的速率调节 在IB CC里面发送方QP通过每次接收到具有BECN比特集的数据包时移动固定的CCTI_Decrese来降低发送速率。逐步降低的速率缓慢,不能迅速消除拥塞。此外,CCT表中预配置和静态的IPD值并不能很好的适应不同的拥塞情况,由于不同的。 其典型拥塞情况可以分为三种: - 端点拥塞,瓶颈是到端点的访问链路。比如如图3,当流si同时向R2发送数据,Link a就成了瓶颈链路,这种拥堵在多对一传输模式中很常见。 - 网络中拥塞,瓶颈是结构内部的共享链接。当流f1和fm分别向R1和R2发送数据时,Link b就成了瓶颈链路。 - 同时多个拥堵点,这是最复杂的情况,通常出现在共享同一链路但瓶颈不同的流的情况下。 比如,当流fi(1<=i<=m-1)向R1和流fm和流si给R2发送数据的同时,他们的链路瓶颈不同经管他们都共享Link a。 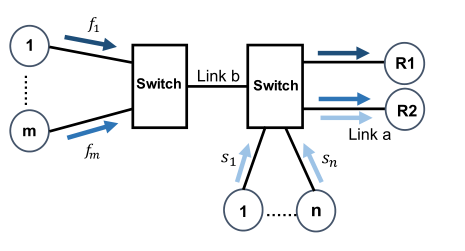 图3 典型的拥塞情况 二、接收者驱动的拥塞流的识别 在IB CC中交换机负责在检测拥塞时区分拥塞根端口。检测拥塞根端口的目的是识别实际的拥塞流,这些拥塞应该在限制速率的情况下进行。人们可能会认为,如果信用额度超过下限,那么可以安全地将一个端口视为拥塞根端口。但是信用的下限很大程度上取决于信用的更新频率和拥塞根端口的拥塞程度。 我们发现接收者拥有识别拥塞流的宝贵信息:对于拥塞流,所有数据包都至少通过一个拥塞根端口,经历了长时间排队,并且始终具有可用信用。而对于非阻塞流,没有任何数据包通过拥塞根端口。我们的解决方案是拥塞识别延迟到接收端, 它的优点是我们避免了深入研究交换机中的实现细节,同时也能够准确地识别拥塞流。 最终我们形成了如图4以接收者驱动的拥塞控制结构。 - 拥塞检测(Congestion detection) - 拥塞标记(Congestion marking) - 拥塞识别(Congestion identification) - 拥塞通知(Congestion notification) - 速率调整(Rate regulation) 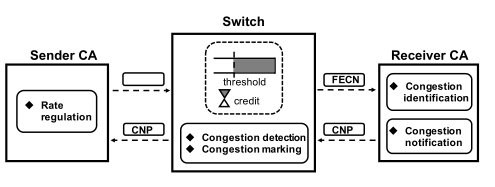 图4 接收者驱动的拥塞控制结构 -------------------------------- ###参考文献 [1]曹光权,张子文,孙志刚,陈洪义,胥庆杰.基于ibdump的InfiniBand网络拥塞控制观测方法研究[J].计算机科学,2013,40(04):47-50. [2]Zhang Y, Qian K, Ren F. Receiver-Driven Congestion Control for InfiniBand[C]//50th International Conference on Parallel Processing. 2021: 1-10. [3]Pfister G F. An introduction to the infiniband architecture[J]. High performance mass storage and parallel I/O, 2001, 42(617-632): 102. [4]Chu C H, Kousha P, Awan A A, et al. Nv-group: link-efficient reduction for distributed deep learning on modern dense gpu systems[C]//Proceedings of the 34th ACM International Conference on Supercomputing. 2020: 1-12. 最后修改:2022 年 05 月 05 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
